The assurance and survivability of information infrastructures are essential to the defense of the nation. Intrusion detection is recognized as a very important component of the critical infrastructure protection mechanisms. Due to the manual and error-prone development process where incomplete "expert knowledge" is codified as the detection models, currently, intrusion detection systems (IDSs) are expensive and slow to develop, difficult to optimize according to local cost-benefit parameters, and ineffective in detecting novel and fast attacks. New technologies are therefore needed to substantially improve the capabilities of IDSs.
We propose a novel system for rapid development and deployment of effective and cost-sensitive IDSs. Our system automates feature construction, the critical step in building effective misuse and anomaly detection models, by analyzing the patterns of normal and intrusion activities computed from large amount of audit data. Detection models are constructed automatically using cost-sensitive machine learning algorithms to achieve optimal performance on the given (often site-specific) cost metrics. Our system finds the clusters of attack signatures and normal profiles and accordingly constructs one light model for each cluster to maximize the utility of each model. A dynamically configurable group of such light models can be very effective and efficient, and resilient to IDS-related attacks. The detection models can be rapidly deployed through automatic conversion to efficient real-time modules of fielded IDSs.
The research team, with researchers from North Carolina State University, Columbia University, and Florida Institute of Technology, has worked together on the JAM project (DARPA F30602-96-1-0311, PI: Sal Stolfo, Columbia University), where agent-based data mining technologies were developed and successfully applied to fraud detection in financial systems and network intrusion detection. The 1998 DARPA Intrusion Detection Evaluation showed that the models produced by JAM's MADAM ID (Mining Audit Data for Automated Models for Intrusion Detection) component had one of the best performance among the participants. This project is a continuation of our collaboration where we will utilize the existing components of JAM and will develop new focused capabilities. In addition, we will leverage our existing relationships with the commercial partners in our STTR projects, namely, Network Flight Recorder Inc. and Reliable Software Technologies Inc., for technology transfer.
Currently, IDSs are developed using pure knowledge-engineering approaches where expert knowledge on network, operating systems, and attack methods are encoded as detection models. These IDSs are not very effective in detecting variations of known attacks and novel attacks because expert knowledge is often incomplete and tends to be too specific to attack instances. Since the manual development process is very slow and expensive, IDSs are often equipped with only one centralized detection module, making them unable to keep up with fast (automated) attacks, and worse, subject to denial-of-service attacks. IDSs are not cost-sensitive because the cost factors, which include the development and operational costs, and the intrusion costs (damages), etc., are simply ignored as unwanted complexities in the IDS life cycle. Because of the lack of these critical capabilities, there has not been a widespread deployment of IDSs, which otherwise could greatly enhance the defense of the nation against information warfare.
We propose a novel system for rapid development and deployment of effective and cost-sensitive IDSs. Our system uses data mining and machine learning programs to automatically construct misuse and anomaly detection models. Compared with other recent research efforts in applying data mining to intrusion detection, our system offers several innovative component technologies that directly address the challenging problems of automatic feature construction, cost-sensitive modeling, light modeling, and efficient real-time scheduling.
An intrusion detection (ID) model has two main elements: the features, which are the "indicators" (evidence), and the modeling algorithms, which serve to piece together and reason about the indicators. Features are therefore the foundation of ID models. We propose an automatic feature selection and construction approach. Data mining programs are first applied to audit data to compute the behavior patterns of normal and intrusive activities. Pattern analysis programs are then used to identify the consistent normal and intrusion patterns, which are then parsed to construct features for anomaly and misuse detection purposes. We will continue our work in developing data mining algorithms, in particular, in the area of incorporating network and system knowledge and attack taxonomy to efficiently compute the relevant temporal and statistical patterns from the large amount of complex and semi-structured audit data. The process of pattern mining, pattern analysis, feature construction, and model construction and evaluation is inherently iterative given that the goal is to build the best model. We will apply workflow technologies to integrate these tools and automate this multi-step process. We will study how to define a set of goal-oriented and auto-focus operators, that at each iteration of the process, can refine (redirect) the tools to produce better results. We believe that our automatic feature selection approach can be used to quickly discover highly predictive features and build effective ID models.
A fielded IDS should bring the most protection (benefit) on the investment (life cycle cost). This requires the ID models be sensitive to cost factors, which at the minimum include the development cost, the operational cost (i.e., the needed resources), the damage cost of missing an intrusion, and the response cost of detecting a potential intrusion. We will develop cost-sensitive machine learning algorithms to automatically construct detection models that are optimized for the overall cost metrics instead of mere statistical accuracy. We will address these main challenges: defining the cost metrics, which specifies the relationships among various cost factors; and building models that can adjust to dynamically changed cost metrics. We believe our research will provide not only the tools but also the science for cost-sensitive modeling.
IDSs that employ a single intrusion detection module can easily become the performance bottleneck because every network packet (or OS event) needs to be checked by a single program. The delay between actual intrusion and detection may be sufficient for fast attacks to successfully perform malicious actions. Denial-of-services attacks can also bring down these systems because there is a single point of failure. We therefore need a decentralized approach where multiple models are combined to provide better detection performance. The main difficulties here are: determining what light models should be built, and combining the models dynamically in a cost-sensitive manner. As a side effect of our feature construction process, we often discover that some attack signatures or normal profiles result in (and thus require) the same set of features. We can utilize this clustering information to build one model, which includes only the required subset of features, for each cluster so that each model is light and its coverage is maximized. We will use meta-learning to automatically construct a combined model from a group of these light models. We will extend meta-learning to be cost-sensitive in the sense that the combined model can use the cost measurements of each light model to dynamically determine what models should be included (activated). We believe that our approach, compared with building a light model specifically for a target resource (e.g., sendmail), is of greater value because it automatically builds light models that have maximal utility while minimizing the overall cost.
Intrusion detection models need to be incorporated into real-time IDSs. We will develop translators to automatically convert our models into modules of programmable real-time IDSs, e.g., Bro and NFR. We believe that our system can play a key role in the rapid deployment of IDSs because each site can apply our system to automatically construct models using local audit data and cost metrics, and then automatically translate the models to obtain a running system. A key requirement for real-time IDSs is fast response (detection) time. Although cost-sensitive learning algorithms already produce models with low computational costs, there is room for improvement. There can very low cost necessary conditions for each intrusion. That is, some feature values must be true for the intrusion to take place. Checking these necessary conditions often incurs lower cost then checking (detecting) the intrusion itself. We will study how to use these low cost necessary conditions to compute an efficient schedule for run-time execution of the ID models.
In summary, our proposed project will study several important and challenging problems in intrusion detection, and will bring the rapid and widespread deployment of cost-sensitive and light IDSs into common practice and general availability.
We propose to build and demonstrate a novel system for rapid development and deployment of effective and cost-sensitive IDSs. This system employs approaches that have solid foundations in statistics, machine learning, information theory, and workflow modeling and management. Our system is to be used as an "intrusion detection model builder". That is, our goal is to provide a set of integrated tools that assist human experts to build ID models that are effective, light and cost-sensitive.
An important objective of this work is to develop generally available tools that permit the automatic analysis of very large amounts of audit data in order to develop new and better models of intrusions. The amount of audit data that can be acquired is vast, and any direct human inspection of that data in order to find new intrusions, or variations of known intrusions, cannot conceivably be done in an effective and efficient manner without automation.
The tools we shall develop for anomaly detection will undoubtedly be useful to analyze and discover new patterns in offline or archived audit data sets to aid in the modeling of new, novel attacks that may have been perpetrated but which were not detected by misuse detection models. It is possible that these techniques may dramatically speed up the time it takes now for human experts to learn of new exploits, and to rapidly develop new models to detect them.
We will develop these main component technologies: automated feature construction, cost-sensitive modeling, light modeling, and efficient real-time execution. We will utilize, as much as possible, the existing components of the JAM system that was developed under a previous DARPA contract (DARPA F30602-96-1-0311, PI: Sal Stolfo, Columbia University). We will also explore the possibilities of technology transfer to commercial IDSs vendors.
For automated feature construction, our goal is to develop a set of integrated tools that can be applied to large amount of audit data to output a set of predictive features for both misuse and anomaly detection purposes. Towards this end, we will develop data mining algorithms for analyzing audit data, pattern encoding and comparison algorithms for identifying normal and intrusion patterns, and pattern parsing algorithms for constructing features from identified patterns. We will put more emphasis on constructing features for anomaly detection models.
For cost-sensitive modeling, our goal is to develop cost-sensitive machine learning algorithms that can automatically construct ID models that are optimized for cost saving rather than pure statistical accuracy. We will study how operational costs (mainly the computational costs of ID models) and damage costs (of intrusions) can be used to guide machine learning algorithms to produce cost-sensitive ID models. We will also study how to construct ID models that can be adaptive to site-specific cost measures.
For light modeling, our goal is to study how to use a group of coordinated light ID models to provide comprehensive coverage for known attacks and anomalies. Towards this end, we will develop clustering techniques to group similar attack signatures and normal profiles so that a light model can be constructed for each cluster. We will study how to apply meta-learning techniques to correlate the outputs of these light models to produce a combined model, and how to incorporate cost factors to prioritize and activate the models at run-time.
For efficient real-time execution ID models, our goal is to develop a set of translation tools so that our ID models can be automatically translated into efficient modules of existing real-time IDSs. We will exploit of the idea of using low-cost "necessary conditions" of intrusions as pre-tests to filter out majority of (unnecessary) rule checking. We will use Bro and NFR as case studies to test and demonstrate our techniques.
We have great success in the JAM project where we developed an integrated data mining and machine learning system for building credit card fraud detection models and network intrusion detection models. Using meta-learning and cost-sensitive learning techniques, we showed that our fraud detection models yield a 7% increase in cost savings for the financial institutions that provided us with the transaction data. Results in the 1998 DARPA ID Evaluation showed that the ID models produced by MADAM ID (for Mining Audit Data for Automated Models for Intrusion Detection), a component of JAM, had one of the best performance among the participants.
The JAM project was under the guidance of Professor Sal Stolfo at Columbia University. Professor Stolfo directed all research activities related to JAM. The architecture of JAM, and its meta-learning technologies were based on Phil Chan's Ph.D. thesis at Columbia University (under the supervision of Professor Stolfo). A faculty with Florida Institute of Technology since 1995, Professor Chan was a member of the JAM project team, and contributed to the development of meta-learning, distributed data mining, and cost-sensitive learning technologies. The MADAM ID component of JAM was developed as part of Wenke Lee's Ph.D. thesis at Columbia University (under the supervision of Professor Stolfo). Dr. Lee developed data mining algorithms, pattern encoding and comparison algorithms, and feature construction algorithms. He also investigated techniques for cost-sensitive modeling and efficient real-time execution of ID models. Dr. Lee is currently a faculty at North Carolina State University.
We have made most of the JAM components available through our project Web page. We have also published extensively in premier machine learning, data mining, and security conferences. We have received a best paper award and two honorable mentions in the last three years. We list the relevant publications as follows.
For automatic feature construction, we will develop:
For cost-sensitive modeling, we will develop:
For light modeling, we will develop:
For efficient real-time execution, we will:
For experimentation and integration, we (NCSU, Columbia, and FIT) will together:
We will ensure that all software and information technology items developed in or related to this project be Y2K compliant. We will make our software available for integration with other research projects, and for technology transfer. We will participate in related IA&S PI meetings, experiments and evaluations (e.g., DARPA ID evaluation), and discussions sponsored by standard bodies (e.g., IETF/IDWG, CIDF, etc.). We will rigorously and scientifically evaluate our techniques, and document and publish the findings in our project.
The outcome of this research consists of theoretical results, performance measurements, implementation strategies, IDS development system, and deployable intrusion detectors.
We will make available two types of software systems. The first is a complete software package, an ID model development system, that will enable IDSs developers to rapidly build effective, cost-sensitive, and light ID models. The completed implementation will include tools that provide automatic feature construction, cost-sensitive modeling, light modeling, and efficient real-time scheduling. Although these tools can each be stand-alone and be integrated with other IA&S systems, they will be integrated through this project into a single working system that has intuitive GUIs and workflows. Most of the components of JAM will be utilized, but much of new development needs to be done to provide new features and capabilities. We will also provide detailed installation, user, and maintenance documents.
The second software system(s) that we will deliver is a real-time IDS(s) that is equipped with the ID models produced by our development system. The extended IDS can be readily fielded in a network environment. The package will include a "standard" (vanilla) IDS, e.g., Bro, and the add-on modules that implement our misuse and anomaly detection models. We will provide a technical document describing the features and models, as well as the sample cost matrix used. We will also provide detailed installation and user manuals, and pointers to the download sites for the standard IDS.
We will conduct rigorous and formal evaluations of performance and utility on an ongoing basis. We will participate in all DARPA organized experiments and evaluations, e.g., DARPA Intrusion Detection Evaluation. We will provide DARPA with written and oral reports detailing the evaluation methodology and empirical performance during each phase of the proposed project. We will make an effort in sharing our findings with other research groups, transferring our technologies to commercial vendors, and publish in major technical conferences.
Intrusion detection is the process of identifying and responding to malicious actions that aim to compromise the security of a system, i.e., its confidentiality, integrity, and availability. The basic premises of intrusion detection are: system activities are observable, e.g., via auditing; and normal and intrusion activities leave distinct evidence. Therefore, an ID model has two basic elements: the features, that is, the indicators (evidence), measured using the audit data; and the modeling algorithms that piece together and reason about the indicators. The two main intrusion detection techniques include misuse detection, which uses signatures of specific attacks or system vulnerabilities to pattern-match and detect intrusions; and anomaly detection, which uses established normal profiles of users or system resources to detect significant deviation as probable intrusion. Misuse detection can be very efficient and accurate, however, by definition, it can detect only the instances of known intrusions. Anomaly detection is the only weapon to detect new attacks, however, it often cannot determine the nature of an attack and can have a high false alarm rate. An IDS therefore needs to carefully combine both misuse and anomaly detection models.
Despite the research and commercial efforts in the past two decades, there are still a large gap between the capabilities of IDSs and that of cyber attackers. Results from the 1998 DARPA Intrusion Detection Evaluation showed that although several intrusion detection programs already showed good detection rates on known intrusions and their slight variations, none of the systems showed acceptable detection rate on "novel" attacks, i.e., those that are not modeled in the detection systems. Most IDSs are designed only to achieve optimal effectiveness (i.e., accuracy). However, for IDSs to be widely deployed, they need to bring economic benefits to organizations. This requires that IDSs balance the requirements of both accuracy and costs, which include development costs, operational costs, damage (intrusion) costs, etc. Real-time IDSs need to avoid becoming a single point of failure because cyber attackers are beginning to devise attacks that aim to elude IDSs through evasion tactics or denial-of-service. Multiple light, fast, and cooperative detection systems are likely to achieve more robust performance than using a monolithic system.
The traditional manual approaches of encoding expert knowledge cannot meet the challenges of building IDSs that are equipped with the advanced capabilities discussed above. To effectively detect novel attacks, an IDS needs to provide comprehensive and systematic coverage, i.e., modeling, of all network elements and their interactions. Expert knowledge is simply too limited compared with the complexities of a network system. The delicate balance between accuracy and various cost factors, and the need to construct multiple cooperative models also add significant complexities in the development process. We therefore need a new development paradigm.
We propose to build and demonstrate a novel system for rapid development and deployment of effective and cost-sensitive IDSs. We consider intrusion detection as a classification problem, that is, we wish to classify each audit record into one of a discrete set of possible categories, normal or a particular kind of intrusion. We can thus apply machine learning approaches to inductively learn classifiers as detection models. Given a set of records, where one of the features is the class label (i.e., the concept), classification algorithms can compute a model that uses the most discriminating feature values to describe each concept. However, before we can apply classification algorithms, we need to first select and construct the right set of system features that may contain evidence (indicators) of normal or intrusions. We will develop an automatic feature selection and construction system to systematically discover and construct predictive features that can be used to build effective misuse and anomaly detection models. We will develop cost-sensitive classification algorithms to construct ID models that are optimized to provide the best economic benefits (cost-saving). We will interact research efforts in security risk assessment that study how to define the various intrusion cost factors. We will study how to automatically construct a group of cooperated light models. We will also study how to efficiently execute ID models in real-time.
The research team, with researchers from North Carolina State University, Columbia University, and Florida Institute of Technology, has previously worked together on the JAM project (DARPA F30602-96-1-0311, PI: Sal Stolfo, Columbia University), where research conducted on JAM and its MADAM ID component demonstrated that effective credit card fraud detection and network intrusion detection models could be built automatically using data mining and machine learning techniques. We have shown that meta-learning techniques can be used to combine detection models from multiple financial institutions to achieve better performance. We also showed that detection models produced using cost-sensitive learning techniques save the financial institutions more money than models that consider only accuracy. The 1998 DARPA Intrusion Detection Evaluation showed that the models produced by JAM's MADAM ID had one of the best performances among the participants. In this project, we will utilize the existing JAM components as much as possible, and will focus on developing new algorithms that will enable the development of effective, light, and cost-sensitive ID models.
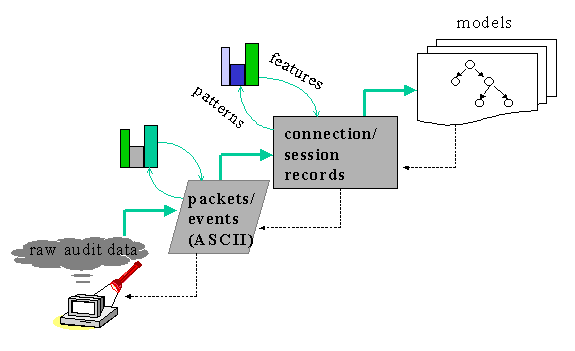
Figure 1. The Data Mining Process of Building Intrusion Detection Models
The process of applying data mining approach to build ID models is shown in Figure 1. Here raw (binary) audit data is first processed into ASCII network packet (or host event data), which is in turn summarized into connection records (or host session records) containing a number of within-connection features, e.g., service, duration, flag (indicating the normal or error status according to the protocols), etc. Data mining programs are then applied to the connection records to compute the frequent sequential patterns, which are in turn aggregated and analyzed to construct additional features for the connection records. Classification programs, for example, RIPPER, are then used to inductively learn the detection models. This process is of course iterative. For example, poor performance of the classification models often indicates that more pattern mining and feature construction is needed. We describe the main component technologies of our proposed approach in the following sections.
There is empirical evidence that program executions and user activities exhibit frequent correlations among system features, e.g., certain privileged programs only access certain system files in specific directories. These consistent behavior patterns should be included in normal usage profiles. The goal of mining association rules is to derive multi-feature (attribute) correlations from a database table. An association rule is an expression X ==> Y [c, s]. Here X and Y are called itemsets. s=support(X union Y), the percentage of records that contain X union Y, is the support of the rule, and c=support(X union Y)/support(X) is the confidence. The goal of mining frequent episode rules, on the other hand, is to capture the frequent sequential (temporal) patterns of co-occurring events. Let interval [t1, t2] be the sequence of event records that starts from timestamp t1 and ends at t2. The width of the interval is defined as t2 - t1. Define support(X) as the ratio between the number of minimum intervals that contain X and the total number of event records. A frequent episode rule is the expression X,Y ==> Z [c, s,w]. Here X, Y and Z are itemsets, s=support(X union Y union Z) is the support, and c=support(X union Y union Z)/support(X union Y ) is the confidence. X, Y, and Z must all occur within w. We need both association rules and frequent episodes in describing network activity patterns.
It is important to incorporate domain knowledge to direct data mining algorithms to find "relevant" patterns efficiently. We have developed several extensions to the basic association rules and frequent episodes algorithms that utilize the schema-level information about connection records in mining frequent patterns. We briefly describe the main ideas here. Observe that a network connection can be uniquely identified by the combination of its time (start time), src_host (source host), src_port (source port), dst_host (destination host), and service (destination port), which are the "essential" attributes of network data. We argue that "relevant" patterns should describe patterns related to the essential attributes. Depending on the objective of a specific data mining task, we can designate one (or several) essential attribute(s) as the axis attribute(s). The frequent episodes algorithm first finds the frequent associations about the axis attributes, and then computes the frequent sequential patterns from these associations. Thus, the associations among attributes and the sequential patterns among the records are combined into a single rule. That is, we combine association rules and frequent episodes into the same formalism.
|
time |
duration |
service |
src_host |
dst_host |
src-bytes |
dst_bytes |
flag |
... |
|
1.1 |
0 |
http |
spoofed_1 |
victim |
0 |
0 |
S0 |
... |
|
1.1 |
0 |
http |
spoofed_2 |
victim |
0 |
0 |
S0 |
... |
|
1.1 |
0 |
http |
spoofed_3 |
victim |
0 |
0 |
S0 |
... |
|
... |
... |
... |
... |
... |
... |
... |
... |
... |
|
10.1 |
2 |
ftp |
A |
B |
200 |
300 |
SF |
... |
|
13.4 |
60 |
telnet |
A |
D |
200 |
2100 |
SF |
... |
|
... |
... |
... |
... |
... |
... |
... |
... |
... |
Table 1: Network Connection Records
Some essential attributes can be the references of other attributes. These reference attributes normally carry information about some "subject", and other attributes describe the "actions" that refer to the same "subject". For example, if we want to study the sequential patterns of connections to the same destination host, then dst_host is the "subject" and service is the action. We use reference attribute in the frequent episodes algorithm to compute the "same subject (reference) patterns". An example frequent episode derived from the connection records in Table 1, with service as the axis attribute and dst_host as the reference attribute, is shown in Table 2. This is a pattern of the "syn flood" attack, where the attacker sends a lot of "half-opened" connections (i.e., flag is "S0") to a port (e.g., "http") of a victim host in order to over-run (i.e., quickly use up) its buffer and thus achieve "denial of service".
|
Frequent Episode |
Meaning |
|
(service=http, flag=S0), (service=http, flag=S0) ==> (service=http, flag=S0) [0.93, 0.03, 2] |
93% of the time, after two http connections with S0 flag are made (to a host victim), within 2 seconds from the first of these two, the third similar connection is made, and this pattern occurs in 3% of the data |
Table 2: Example Frequent Episode Rule
We can create a set "baseline" normal patterns to describe the normal behavior of network traffic. We mine patterns from each subset (e.g., each day) of normal network connection records, and incrementally merge the patterns to form an aggregate pattern set, where rules that have similar (left-hand-side) LHS and (right-hand-side) RHS, and support and confidence values are combined into a single rule. This is done for each possible combination of axis and reference attributes, and until the pattern set becomes stabilized, i.e., very few patterns can be added from a new audit data set. Then for each data set that contains an intrusion (or its simulation run), we can mine frequent patterns from it, and compare the patterns with the normal baseline to identify the intrusion-only patterns, that is, those that are resulted from the intrusion data set.
The aggregate normal pattern set is usually very large, in the range of several thousands to tens of thousands of patterns. We have developed an encoding scheme to convert each frequent pattern to a number so that we can easily visualize (and thus understand) and efficiently compare the patterns. The main idea behind our encoding scheme is to map patterns that are structurally and syntactically more "similar", that is, those with similar values on the similar set of attributes, to closer numbers. The comparison of two patterns can then be implemented as calculating the diff scores (bit-wise subtraction) between the two encodings, i.e., the numbers. Given the baseline normal patterns and patterns from an intrusion dataset that are computed using the same choices of axis attribute(s), reference attribute(s), support, confidence, and window requirements, we can identify the intrusion-only patterns by comparing the encoding of each pattern from the intrusion detection data set with that of each normal pattern, and keeping the lowest diff score as its "intrusion" score. At the end of the process, we output the patterns that have non-zero intrusion scores, or a user-specified top percentage of patterns with the highest "intrusion" scores. For example, since there is no normal pattern with flag=S0 in all its itemsets, the diff score for the "syn flood" pattern is very high, and thus it will be identified as intrusion pattern.
The operations described above can identify patterns of many PROBING and DOS (denial-of-service) attacks because they typically involve many connections within a time window. However, there are many intrusions that are embedded within a single connection, or just a very few connections. These intrusions may not result in any "frequent" patterns due to the support and confidence thresholds used in the data mining algorithms. There are two approaches to deal with this problem. The first is to perform pattern mining and comparison using ASCII packet level data, where each "record" is information about a packet. Our experiments showed that intrusion patterns can indeed be identified at the packet level data for some attacks, for example, those that use a lot of fragmented packets or "urgent" packets. We will develop a more general approach that does not require intrusion patterns to be "frequent". We will describe this approach in section "Feature construction for anomaly detection", but note that it is also applicable for misuse detection.
Each of these frequent normal patterns is used as a guideline for adding additional features into the connection records to build better classification models. The main ideas of the automated procedure for parsing a frequent episode and constructing features are described as follows.
This procedure parses a frequent episode and uses three operators, count, percent, and average, to construct temporal and statistical features. The intuition behind this algorithm comes from the straightforward interpretation of a frequent episode. For example, if the same attribute value appears in all the itemsets of an episode, then there are a large percentage of records (i.e., the original data) that have the same value. We treat the "essential" and "non-essential" attributes differently in order to construct general features that are applicable to a class of intrusions. The "essential" attributes describe the anatomy of an intrusion, for example, "the same service (i.e., port) is targeted". The actual values, e.g., "http", is often not important because the same attack method can be applied to different targets, e.g., "ftp". On the other hand, the actual "non-essential" attribute values, e.g., flag=S0, often indicate the invariant of an intrusion because they summarize the connection behavior according to the network protocols. As an example, the "syn flood" pattern results in the following features: a count of connections to the same destination hosts in the past 2 seconds, and among these connections, the percentage that are to the same service, and the percentage that have "S0" flag.
When building anomaly detection models, we can only assume the availability of normal audit data. The goal is to build comprehensive models that cover wide varieties of normal behavior. We use the deviation on each of the frequent normal patterns as a feature. That is, if we have n patterns, say, numbered 1 through n, then we have n features, each being a measure on the deviation of the pattern i. When checking a given audit data set with the patterns, the deviation value is calculated as follows: if the pattern is matched, it is 0; otherwise, it is the product of the confidence and support of the pattern. We will develop efficient pattern checking algorithm so that deviation values can be computed quickly. We utilize patterns from both packet-level data and connection-level data. At the packet-level, the vector of deviation values is completed when all packets of the connection is examined. At the connection-level, the vector is completed when the connection is ended and the data on past connections are examined (for the across-connection patterns). The two vectors are then merged into a single vector for the current connection. This vector of deviation values is essentially a description of how well the connection is conforming to the normal baselines, i.e., the normal profiles, of packet-level and the connection-level. We will study how to "combine" the features into fewer and more general features, especially when n is a very large number. For example, patterns related to SYN can be grouped to output a deviation as "SYN error", likewise a "FIN error" for patterns related to FIN, "fragmentation error", and "per-host traffic intensity", etc. Note that this approach can also be used to identify features for misuse detection. Basically, given an audit data set that contains a known intrusion, we can use the most violated (i.e., those with highest deviation values) normal patterns to construct appropriate features.
We will develop and apply classification algorithms for learning anomaly detection models from the packet records and the connection records. A challenging issue here is what do we use as the class label. There are several alternatives. For example, we can use service, or dst_host, etc., as the class label. Here, the learned rule describes what the normal behaviors of each network service or host are, in terms of acceptable deviations from the normal profiles. In executing these rules, a classification error, e.g., the fact that an actual "http" connection is classified as "telnet" indicates that the "http" connection is behaving out of character, and hence there is an anomaly. And the default (i.e., everything else) is "abnormal" which is fired when none of the rules (describing normal behavior) matches. To provide the best protection, it is desirable that we create one anomaly detection model for each network element, e.g., service, host, etc. However, this exhaustive approach is clearly not economical both for development and operations. We will study how to group the network elements into proper "groups", e.g., using network configuration information or "similarity measures" on feature vectors, so that each one model can be built and shared by the group members. A separate anomaly detection model can then be learned for each of these groups. Meta-learning, a hierarchical machine learning process, can be applied to automatically build a network-wise global models that combine the outputs of the individual models.
We will also study a method for detecting anomalies using a probabilistic framework. In our probabilistic approach, an "anomaly" is defined to be an example that has a very low probability of occurring under normal circumstances. Given a large dataset, we can construct a probabilistic model over the data. An anomaly is an example whose probability is less than some threshold. Using this framework, an anomaly detection problem can be reduced to determining the probabilistic model. In order to effectively detect anomalies, the probabilistic model must accurately capture the likelihood of the data. We have developed an efficient algorithm that can induce Sparse Markov Chains (similar to HMMs), which can model sequential data such as TCP dump or BSM audit data. This algorithm is designed to efficiently extract a pattern even when there is noise in the data. This feature will allow good performance over the type of data in the intrusion detection task. This algorithm creates a Sparse Probabilistic Suffix Tree (SPST) that can be used to determine the probability of a given sequence.
There are several issues that an anomaly detection system must take into account. The first is the feature set from which to detect anomalies. The second is determining the type of a detected attack. Finally, the anomaly detection system must perform within a tolerable false alarm rate.
The feature set from which the anomalies are detected are the TCP dump data and the BSM or NT log data. Since this data is sequential, we can apply the Sparse Markov Chain algorithm to estimate the probability distribution over the sequence. This is done by mapping each TCP packet, BSM record, or base object audit record to a symbol in a specially defined input alphabet. Each symbol in the input alphabet has a set of features that correspond to the variations in the TCP packet, BSM record, or NT base object. The specific variations and the prior probability distribution can be defined to incorporate prior knowledge into the detection system. The system will then induce a probability distribution over each sequence of data. When monitoring for anomalies, the system will identify sequences of input with very low probability and flag them as anomalies.
In order to determine the type of attack (u2r, dos, r2l, etc.) that corresponds to an anomaly, we will label branches of the SPST with the labels of known attacks that correspond to those branches. This is done by using the tree to analyze the traces of known attacks and recording where the attacks occur on the tree. Each node in the tree will be labeled with the closest known attack label to that node. When an anomaly is detected, the system will label the anomaly with the label of the closest known attack.
We expect a tolerable false alarm rate because our system will give us a likelihood for an anomaly. Depending on this likelihood, we can decide whether or not to act on the anomaly immediately or perform some other kind of analysis on that connection. We can tune the responsiveness of our system to keep our performance within a tolerable false alarm rate. However, because we will closely couple our anomaly detection system within a larger intrusion detection framework, even detected anomalies which are below the likelihood threshold to generate an alarm can be useful because they can sensitize other detectors in the IDS to analyze the suspect connection(s) more closely.
Our experience showed that the choice of axis and reference attributes is very important in computing the intrusion patterns. For example, "port-scan" is an intrusion where the attacker typically makes connections to many ports (i.e., using many different services) of a host in a short period of time. A lot of such connections will be rejected since many ports are normally closed. Using dst_host as both the axis and reference attribute produces very distinct intrusion patterns, for example, (flag=REJ, dst_host=hostA) ==> (flag=REJ, hostA). But no intrusion pattern is found when using other combinations of axis and reference attributes.
We need to alleviate the user from the burden of "guessing" these choices. We can apply workflow management technologies to automate the iterative process that involves pattern mining and comparison, feature construction from patterns, and model building and evaluation. We will develop a set of "goal-oriented" and "auto-focus" workflow operators that select a different combination of axis attribute and reference attribute for data mining and feature construction at each iteration. The resultant detection models are then compared with the models from the previous iterations in terms of performance. Depending on whether an improvement is achieved, the workflow operators determine what new combination of axis and reference attribute ought to be used in the next iteration, or what combination of features of all iterations should be used to build models. The set of features that results in the best models is selected at the end of this procedure. We will also study how to use attack taxonomy data to guide the operators to quickly identify the best features and models.
Before we conclude this section, we need to emphasize that our feature construction process is not intended to be exclusive. Human experts can participate in the process in deciding of what frequent patterns should be used for the automatic feature construction procedure, and in accepting or rejecting the constructed features. Further, they can input features that are based on their expert knowledge to make the feature set as comprehensive as possible.
We will collaborate with research efforts in computer security risk assessment to study the various cost factors related to IDSs. We have identified and will discuss the following three types of costs: damage cost: the amount of damage caused by an attack if intrusion detection is not available or an IDS fails to detect an attack; challenge cost: the cost to act upon a potential intrusion when it is detected; and operational cost: the resources needed to run the IDS. Damage can be characterized as a function that depends on the type of service and attack on that service, DCost(service, attack). The challenge cost is the overhead, which is the cost of acting on an alarm. Operational cost is the computational cost to run a model, which mainly include the feature computational cost used by IDS models. We next elaborate on each of these sources of cost.
Damage Cost: The damage cost characterizes the amount of damage inflicted by an attack when intrusion detection is unavailable (the case for most systems). This is important and very difficult to define since it is likely a function of the particulars of the site that seeks to protect itself. The defined cost function per attack or attack type should be used here to measure the cost of damage. This means that rather than simply measuring FN (false negative) as a rate of missed intrusions, we should measure total loss based upon DCost(s,a), which varies with the service (s) and the specific type of attack (a). These costs are used throughout our discussion.
Challenge Cost: The challenge cost is the cost of acting upon an alarm that indicates a potential intrusion. One might consider dropping or suspending a suspicious connection and attempting to check, by analyzing the service request, if any system data have been compromised, or system resources have been abused or blocked from other legitimate users. (Other personnel time costs can be folded in including gathering evidence for prosecution purposes if the intruder can be traced.) These costs can be estimated, as a first cut, by the amount of CPU and disk resources needed to challenge a suspicious connection. For simplicity, instead of estimating the challenge cost for each intrusive connection, we can "average" (or amortize over a large volume of connections during some standard "business cycle") the challenge costs to a single (but not static) challenge cost per potential intrusive connection.
Operation Cost: The cost of fielding a detection system is interesting to consider in some detail. In the work on fraud detection in financial systems, we learned that there are a myriad of "business costs" involved in design, engineering, fielding and use (challenge) of detection systems. Each contributes to an overall aggregated cost of detecting fraud. The main issue in operational costs for IDS is the amount of resources to extract and test features from raw traffic data. Some features are costlier than others to gather, and at times, costlier features are more informative for detecting intrusions.
Even if one designs a good detection system that includes a set of good features that well distinguish among different attack types, these features may be infeasible to compute and maintain in real time. In the credit card case, transactions have a 5-second response constraint (a desired average waiting time). That's a lot of time to look up, update and compute and test features, per transaction. (Throughput are easily managed by disjoint partitioning of account records among distributed transaction processing sites.) In the IDS case, the desired average response rate should be measured in terms of average connection times, or even by TCP packet rates, a much smaller time frame, so connections can be dropped as quickly as possible before they do damage. Hence, there is very little time to look up. Ideally, we would like to detect and generate an alarm during an on-going attack connection in order to disable it, rather than after the fact when damage has already been done. However, certain models of intrusive connections may require information only known at the conclusion of a connection! Thus, properly designing an intrusion detection system requires that considerable thought be given to the time at which detection can and should take place.
FN cost, or the cost of NOT detecting an attack, is the most dangerous case (and is incurred by most systems today that do not field IDS's). Here, the IDS "falsely" decides that a connection is not an attack and there is no challenge against the attack. This means the attack will succeed and do its dirty work and presumably some service will be lost, and the organization losses a service of some value. The FN Cost is, therefore, defined as the damage cost associated with the particular type of service and attack, DCost(s,a).
TP Cost is the cost of detecting an attack and doing something about it, i.e. challenging it. Here, one hopes to stop an attack from losing the value of the service. There is a cost of challenging the attack involved here. When some event triggers an IDS to correctly predict that a True attack is underway (or has happened), then what shall we do? If the cost to challenge the attack is overhead, but the attack affected a service whose value is less than overhead, then clearly ignoring the attack saves cost. Probes are often cited as doing no damage, and so they can be "reasonably" ignored. However, organizations may behave inappropriately and challenge probes at great cost anyway. If indeed an organization attributes high costs even to Probes, then challenging probes is warranted. If not, then in evaluating an IDS, it is not wise to give it high scores for detecting all probes, but doing poorly perhaps on other more dangerous attacks. Therefore, for a true positive, if overhead > DCost(s,a), the intrusion is not challenged and the loss is DCost(s,a), but if DCost(s,a), the intrusion is challenged and the loss is limited to overhead.
FP cost. Let's take a quick look at FP. When an IDS falsely accuses an event of being an attack and the attack type is regarded as high cost, a challenge will ensue. We pay the cost of the challenge (overhead), but nothing really happened bad except we lost overhead on the challenge. Naturally, when evaluating an IDS we have to concern ourselves with measuring this loss. For this discussion, we define the loss is just overhead for a false positive.
TN cost. Then there is clearly the TN Cost that remains in this discussion. An IDS correctly decides that a connection is normal and truly not an attack. We therefore bare no cost that is dependent on the outcome of an IDS.
Thus far we have only considered costs that depend on the outcome of an IDS, we now incorporate the operational cost, OpCost, which is independent of the IDS' predictive performance. Our notion of OpCost mainly measures the cost of computing values of features in the IDS. We denote OpCost(c) as the operational cost for a connection, c.
We now can describe the cost-model for IDS. When evaluating an IDS over some test set S of labeled connections, c in S, we define the cumulative cost of IDS as follows:
CumulativeCost(S) = sum over all c in S (Cost (c) + OpCost(c)). Cost(c) is defined as:
|
Outcome |
|
Conditions |
|
Miss (False Negative, FN) |
DCost(s,a) |
|
|
False Alarm (False Positive, FP) |
overhead |
if DCost(s,a) > overhead or |
|
|
0 |
if DCost(s,a) <= overhead |
|
Hit (True Positive, TP) |
overhead |
if DCost(s,a) > overhead or |
|
|
DCost(s,a) |
if DCost(s,a) <= overhead |
|
Normal (True Negative, TN) |
0 |
|
where s is the service requested by connection c and a is the attack type detected by the IDS for the connection.
Cost-sensitive Machine Learning Techniques
Reducing Cumulative Misclassification Cost
Misclassification cost is the cost of emitting a wrong prediction such as predicting an intrusion as a legitimate connection or as a wrong type of intrusion. Traditional machine learning techniques assume that all instances have the same misclassification cost and there is no cost to obtain predictive features used in the model. In IDS domain, there are different costs associated with different types of intrusions. Some intrusions (such as buffer overflow) are more harmful than others (such as port scan) and ought to be caught. Different types of intrusions can be given different cost factors in proportion to their total cost measurements which include both damage cost and challenge cost.
In previous research, we have proposed a generic algorithm called AdaCost that reduces the misclassification cost of an induction algorithm. AdaCost produces a weighted-voting ensemble of classifiers. During learning, AdaCost maintains a distribution over the training set. A distribution is a weight that is given to each example. Examples that are difficult to learn and costly receive more weight or more attention from the learner. AdaCost proceeds in several iterations. At each iteration t, it learns a classifier, ht, from the training set with the current distribution. This classifier is sent back to predict against this training set. Misclassified instances receive higher distributions and correctly classified instances receive lower distribution. A misclassification cost factor is assigned to each example in proportion to their misclassification cost. Misclassification cost factor guarantees that costly examples receive high weights. We formally proved AdaCost reduces cumulative misclassification cost at each round of boosting. The final classifier is a weighted voting ensemble of all the classifiers learned at each iteration, sum over all t (atht(x)), where t is the iteration index, a t is the weighted assigned to hypothesis ht learned at iteration t. Empirical evaluation on the credit card fraud domain has shown a reduction (savings) in cost of 7% for the banks compared with using models that consider only accuracy.
Cost-sensitive Feature Selection
On the other hand, obtaining predictive features in the model may require different levels of computational power and causes delays in real-time auditing. This is part of the operational cost is running an IDS. Different features can also be given cost factors that are linear in their computation overhead. The feature cost-sensitive (fcs) learning algorithm is applied to search for subset of cheap features. We experimented with modifying RIPPER's search heuristics to make it sensitive to feature costs. Let Gain(A) be the FOIL information gain in RIPPER that evaluates a conjunct involving attribute A, and let Cost(A) be the cost of computing a value of A, we can use the following formula as the evaluation function:
(2Gain(A)-1) / (Cost(A) + 1)w
Here w in [0,1] is a constant that determines how sensitive is the cost versus information again. Different types of intrusions can use different w values. For example, for the very damaging intrusions, it is desirable to have a model that is as accurate as possible, without much consideration on the costs of the features. And for intrusions that cause little harm, it is desirable to have a model that is very cheap even if accuracy is sacrificed. Experiments on IDS data set have shown that it builds models from cheap feature subsets, but maintains the original level of accuracy.
While AdaCost is sensitive to misclassification/damage cost and fcs-RIPPER considers feature/operational cost, either of which does not consider both types of cost. In addition, prediction by using the voting ensemble computed by AdaCost requires firing multiple classifiers, which increase operational cost. On the other hand, fcs-RIPPER has to be given a complete feature set, and the chosen features are based on its greedy search heuristic. Moreover, fcs-RIPPER only works for RIPPER; if another learning algorithm is used, it has to be modified and incorporates a suitable heuristic. Hence, we propose a "cascaded" version of AdaCost that is sensitive to both feature and misclassification costs. It combines AdaCost, an induction algorithm as the "black box" base learner and "wrapper" model feature selection. "Cascaded" AdaCost aims to reduce misclassification costs and chooses computationally efficient features. Unlike fcs-RIPPER, AdaCost provides an additional parameter that can be used to adjust the number of features used in the ensemble at different stage.
"Cascaded" AdaCost works in several iterations. At the first iteration, we provide the underlying induction algorithm only a subset of features that are computationally cheap. The model trained from this feature subset will be evaluated against all types or labels of intrusions and a precision, defined as: #true positives / #predicted positives, will be calculated for each type. This measurement is recorded for use in the prediction stage. At the next iteration, more features (with relatively higher computational costs) will be included in the feature subset and a new classifier is computed. A new set of precision values is calculated against all types of intrusions. This process is repeated until either all available features are included or the misclassification cost can no longer be reduced. Early stopping is possible if the misclassification cost has been lowered to a desirable level. In real-time detection, prediction is performed in a cascaded manner. In other words, only the necessary classifiers will be used for predicting. The values of the first set of features are given to the first classifier to make a prediction. If the precision of this prediction (i.e., an intrusion type) is above a desired threshold, the prediction will be issued. Otherwise, more features will be computed and included and more classifiers will be used. That is, features are only computed as needed. Moreover, different transactions could require different resources in both training and testing. We can use precision to represent the operational cost we are willing to pay. Difficult transactions may require more classifiers and more features.
Dynamic Cost Model
In the intrusion detection domain, the cost of different types of intrusions or misclassification cost varies from institution to institution. The training process is long and requires a lot of computational resource. It will be desirable if we can compute one model and fit it for different cost models. This can be done via probability theory. We assume the following notations: i is the true label, P(i|x) is the probability for instance x to be classified as i. C(i,j) is the misclassification cost to classify an audit record with true label i as label j, which will be defined by the institution where an IDS is installed. P(i|x) can be supplied from the model easily. If the induction algorithm is decision tree, rule learner, or naive BAYES, this measure is readily there. For decision tree, P(i|x) can be the weight at the predicting leaf; for rule learner, P(i|x) can be the confidence to fire a rule, and for naive BAYES, P(i|x) can be the posterior probability. Otherwise, we can use kernel density analysis or bagging to obtain P(i|x). The expected misclassification cost to predict label j on example x is the following: EC(j,x) = sum over all i ( P (i|x)C(i,j). Based on Bayesian optimal decision theory, we should choose a label j that has the lowest expected misclassification cost, in other words, j = argminj(EC(j,x)). For cascaded "AdaCost", the same approach can be applied where we use a uniform cost factor for all training instances. This "cascaded" AdaCost with uniform cost factor minimizes on accuracy and chooses computationally efficient features subsets at each round. The final decision is the label that minimizes the weighted expected cost from all participating classifiers in the ensemble, argminj(sum over all t (atECt(j,x))), where t is the iteration index, at is the weighted assigned to hypothesis ht learned at iteration t. The application of Baysian optimal decision theory has been used by other researches for cost-sensitive prediction and obtained good results.
In order to conduct experiments to evaluate various cost-sensitive modeling techniques, and in general, to gain better understanding of the principles of cost-based intrusion detection, we need to use actual measurement of the various cost factors. Damage and challenge costs are often specific to organizational policies. We will collaborate with other research groups, e.g., those in risk assessment, and the user communities to obtain data on these measures. The actual cost values are not important, but the relative "scale" would be quite useful in our studies. For example, if we know that "buffer overflow" is ten times more damaging than "port scanning", the intrusion with the least damage cost, then we can assign "buffer overflow" a damage cost of 10 and "port scan" a damage cost of 1. We can do likewise with the challenge costs.
As a first cut in our research, operational costs can be simplified as feature costs, that is, the computational costs for the features. The computational cost of an ID model is the sum of the costs of its features because the execution (checking) of an ID model involves computing and testing its features. Focusing on computation costs has the advantage that we can have cost measurements for computing efficient real-time schedule for the ID models, as discussed in section I.1.6. Since computational costs are related to the definition of the features, they are often site-independent. Therefore an efficient real-time schedule may be applicable to many installation sites.
We consider these two time factors as the computational costs of a feature: the time spent on waiting for the computation to be ready, that is, for example, the delay between the arrival of the first packet of a connection and the moment that all information is available for the feature to be computed; and the time spent of actually computing the feature, that is, the delay between the readiness of computation and the availability of the result. We can use the sum of these two time factors, i.e., the total time delay between the first packet and the moment that the feature is computed, as the cost of a feature.
We will perform experiments to measure the computational costs, i.e., time delays, of various features. The approach is to modify existing real-time IDSs, e.g., Bro or NFR, to record the time delay when computing each feature from the raw audit data. We will perform multiple runs of normal and intrusion traffics for each feature, and take the average of the computed delays as its cost.
In the feature construction process a set of features is constructed (and thus identified) for each attack or normal profile. Using only the set of features identified for an attack type, we can construct an ID model specific to distinct attack types. These models are lighter than a single monolithic (heavy) ID model that attempts to detect all known attack types and utilizes all the corresponding features. Furthermore, the light models can be strategically placed at locations closer to the data source to reduce the impact of moving large amounts of data from the source to the ID models.
Though each individual light ID model can signal their corresponding attack types, some of these models might be too sensitive and generate unwanted false alarms. To reduce the likelihood of false alarms, we also pool signals for the ID models and consider correlations among them. This is achieved by applying meta-learning to the signals. Meta-learning attempts to identify the correlations among the models' behavior as well as their relationships with the true outcome (under attack or not). During execution, the generated meta-model gathers signals from the light base ID models and makes the final decision. The efficacy of meta-learning has been demonstrated in various domains, including credit card fraud detection and computer intrusion detection. Although the light base models are distributed and some of them could be far away from the meta-model, the cost of transporting these signals is much less than that of transporting large amounts of data to a single heavy ID model. Furthermore, compared to a heavy approach, our modular meta-learning approach makes adding (or removing) base ID models (attack types) a relatively easy task since the change only requires re-learning of the meta-model, not manually modifying the software code as in the case for a heavy model. As we will discuss later, our modular meta-learning approach also purposely aims for scalability and adaptiveness.
Clustering Light Models
We often discover that some attack signatures share a large percentage of common features, for example, attacks A and B use five and six features respectively, but four features are common to both. These attacks profiles can be considered as "similar", and can be grouped into clusters. We can build one model for each cluster, using the union of the features for each attack or normal profile in the cluster. These models are not as light as or cannot be placed as close to the data source as the ones detecting only single attack types, but they have the advantage of not necessitating recalculation of the common features in each model. This is particularly important when some of the features are computationally expensive and sharing features among models can improve efficiency. Furthermore, grouping ID models (hence attack types) can potentially detect unknown attacks that are hybrids of the attack types in the cluster. The performance tradeoff between clustering and not clustering is unknown and will be studied systematically. Particularly, we plan to investigate the following two issues:
We plan to evaluate the performance on novel attack types by deliberately removing an attack type from the training data and study whether it can be detected or not during evaluation. Systematically, a different attack type is removed in each evaluation. Computational cost used in calculating the features in various configurations will also be measured.
Scalability and Temporal Adaptiveness
To develop a realistic IDS, our approach needs to be scalable to handle a continuous stream of large amounts of data. Furthermore, since attack behavior changes and new attack types constantly surface, our system needs to be adaptive to temporal changes as well. We propose a three-tier approach to generating and managing ID models. To illustrate the idea, we use days and months for the first and second tiers respectively, though finer or coarser granularity can be used.
The first tier is per day. We construct features for each day based on normal and intrusive event data. An ID model is generated for each intrusion type for that day. The second tier is per month. We take the "union" of all the features for the month and generate an instance for each day. So for each attack type and we have a month worth of instances, from which an ID model is generated using a learning algorithm. One key characteristics of learning is generalization, and generalization can help fill possible holes in attack signatures not observed in the training data. The third tier is to manage and combine ID models from different months. Base models in past months are evaluated on data of the current month; those that perform above a certain predefined threshold are kept and the others are discarded (or put in a recycling bin for later evaluation and possible adoption). The selected relevant models are then combined via meta-learning. This process is repeated each month to update the overall (meta) model according to the most recent data. That is, our approach is adaptive to temporal changes in attack behavior. Also, it allows the processing of a continuous stream of large amounts of data in relatively small chunks, whose models are then combined to provide the needed scalability.
Concretely, for the third tier, let Dnew be the latest batch of data and Mnew be the set of models generated from Dnew. Also, let Mcurrent be the set of models currently in use. Since Mnew has the most recently mined concepts, it can be safely kept. However, the behavior of the current models Mcurrent on Dnew is evaluated--models in Mcurrent that perform poorly on Dnew are removed from Mcurrent. After this pruning process, models in Mnew are added to Mcurrent and a new meta-classifier is generated via meta-learning. This process is repeated for each new batch of data as it arrives. That is, guided by new data, new knowledge is incorporated and irrelevant knowledge is identified and forgotten. A more sophisticated approach would include old data in the evaluation of Mcurrent and allow data to be weighted according to "age"--weights decay over time.
Also, we can retain the removed models in Mold (recycling bin) and evaluate them along with those in Mcurrent. This way, if previously deemed irrelevant attack types become relevant with respect to the newest data, they are added back into Mcurrent. Although we can be conservative and do not discard models in Mold, we cannot retain every model, unless storage space is not a concern. This dilemma is akin to deciding what to keep or get rid of in the house--some junk could be useful some time in the future. One simple strategy is to keep track of the last time each model was in Mcurrent and models that have not been used for a predetermined period of time are removed permanently. If we have a fixed amount of space for Mold, replacement strategies can be devised to remove models in Mold permanently to make room for others. In one strategy the least recently used (LRU) models are removed first (similar to the LRU strategy in memory page replacement in operating systems). Another strategy is least frequently used (LFU). It calculates the usage rate of each model since its creation (the number of times participated in Mcurrent divided by age) and the ones that have the lowest usage are replaced first. Both LRU and LFU bear some resemblance to how humans forget--we tend to forget items (e.g., skills and information) that we have not used for the longest time or have rarely used. Another approach is to rank models in Mold according to their performance on data at different time periods weighted by a time decay factor and then remove those with lower performance. Forgetting old irrelevant learned knowledge has not been widely studied in the machine learning community.
We plan to evaluate the effectiveness of the three tiers. In our previous work we have demonstrated some success in the first tier. Hence, our proposed research focuses on the second and third tiers. Besides the effectiveness of the tiers, we plan to investigate the temporal granularity of each tier. As we mentioned earlier, the granularity of days and months for the first and second tiers are for the illustration of our approach, we need to experimentally determine if, for example in the first tier, a day worth of data are sufficient (or more than sufficient) to generate accurate and cost-effective ID models. Systematically varying the time period of training data and measuring the performance can help us determine an appropriate temporal granularity at each tier.
Cost Adaptiveness
As we discussed earlier in Section I.1.4, costs in IDS can be categorized into: operational, challenge, and damage costs. These costs do not necessarily stay constant over time. Hence, to continuously minimize the cost of attacks, we would need to devise means of adapting to changes in cost.
Operational cost mainly stamps from the price of computing the values of features used in an ID model. This cost may decrease due to the availability of faster auditing hardware and software. Challenge and damage costs can be considered jointly as in the credit card fraud detection task in our previous study. These costs are not only incurred from computational activities, but also from labor in responding to an alarm, labor in recovering lost services and/or data, loss in productivity, and so on. They are generally set by organizations in their institutional policies. These cost can be reduced if challenges to attacks are more streamlined or damages can be localized or rectified easier.
For learned ID models, changes in operational (feature) costs are more problematic than changes in challenge/damage costs. (To simplify our discussion in this section, we will use the term "damage costs" to include both "challenge and damage costs".) Since the structure of a learned ID model is determined partly by the feature costs, variations in feature costs may demand a change in the structure. For example, a feature might become relatively much more expensive than the others and dropping it from the model would lower the computational cost to achieve "real-time" detection. That is, the model has to be re-learned. On the other hand, changes in damage costs are more related to the predictions of the models and can be addressed without changing the internal structures within an ID model. Comparing changes in feature costs and those in damage costs, we suspect the latter ones are possibly more frequent since an organization naturally wants to take steps to minimize damages as much as possible.
Changing feature costs necessitates re-learning the ID model. As we discussed in Section I.1.4, a feature-cost-sensitive version of RIPPER called fcs-RIPPER was proposed. This algorithm can be used to generate a cost-effective model based on the new feature costs.
Variations in damage costs can be adapted by adjusting the outcome without re-learning the ID model. Our approach, as discussed in Section I.1.4, is to calculate the cost for each possible outcome and predict j with the lowest expected cost according to: sum over all i (P(i|x)* C(i,j), where P(i|x) is the probability of the true label i given instance x and C(i,j) is the cost of predicting label j when the true label is i.
In the context of our modular three-tier approach to scalability and temporal adaptiveness (as discussed in the previous section), we just addressed cost adaptiveness in learning ID models in the second tier. The first tier currently is not cost-sensitive. The third tier involves meta-learning from the behavior of the second-tier models. Since, in meta-learning, the outcomes of the second-tier models become the features of the third-tier models, changes in damages cost of the outcomes become changes in feature costs in the third-tier model. That is, the third-tier model needs to be re-learned.
As we discussed earlier, changes in damage costs are possibly more frequent than the ones in operational/feature costs. That is, in our three-tier approach, in many cases, the second-tier ID models need not be re-learned, only the third-tier meta-model needs to be retrained. Since there is only one third-tier meta-model, re-learning it based on new damage cost will not require large amounts of computation. Furthermore, the updating of the meta-model can be performed in conjunction with the update needed for temporal adaptiveness (as discussed in the previous section). That is, additional computation can be avoided if we coincide cost changes with temporal updates. For fluctuations in feature costs, as we discussed, we need to retrain the second-tier models. Since quite a number of second-tier models exist, computationally, it might be too expensive to retrain all the second-tier models. However, if we can decide which second-tier models are too expensive, we can remove them and retrain the third-tier meta-model. Alternatively, we replace the expensive second-tier models with "dummy" models that always predict "normal". Using this approach, the third-tier meta-model need not be updated since the third-tier meta-model still sees the same number of second-tier models. Though this alternative is computationally attractive, replacing expensive models with "dummy" models essentially changes the behavior of the second-tier models and this might throw off the third-tier meta-model.
To summarize, we proposed techniques for adapting to changes in feature and damage costs and identified possible tradeoffs between effectiveness and efficiency. Systematic experimentation will be performed to evaluate these techniques and investigate their tradeoffs.
Our ID models are produced off-line. Effective intrusion detection should be in real-time to minimize security compromises. We will therefore study how to convert our models for real-time environments. Notice that for a detection rule produced off-line, for example, the RIPPER rule for "ping-of-death",
pod :- wrong_fragment >= 1, protocol_type = icmp.
can be automatically converted into the following real-time execution module of an IDS, e.g., NFR or Bro:
filter pod() {
if (wrong_fragment() > 1 && protocol_type() == icmp)
alarm_pod ();
}
as long as the features, i.e., wrong_fragment and protocol_type, have been implemented as subroutines of the IDS. We will implement a translation mechanism so that our models can be automatically incorporated into real-time IDSs. We plan to use Bro and NFR as test cases.
Although often ignored in off-line analysis, efficiency is a key consideration in real-time intrusion detection. If we try to follow the off-line analysis steps in a real-time environment, then a connection is not inspected (i.e., classified using the rules) until its connection record is completely formulated, that is, all packets of the connection have arrived and summarized, and all the temporal and statistical features are computed. When there is a large volume of network traffic, many connections may have terminated (and thus completed with attack actions) when the current connection is finally inspected by the rules. That is, the detection of intrusions is severely delayed. Ironically, DOS attacks are often used by intruders to first overload an IDS, and use the detection delay as a window of opportunity to quickly perform their malicious actions, e.g., they first disable the IDS.
We need to examine the time delay associated with each feature in order to speed up the model execution. The time delay of a feature includes not only the time of its computation, but also the time of its readiness (i.e., when it can be computed). For example, the flag of a connection can only be computed (summarized) after the last packet of the connection has arrived, whereas the service of a connection can be obtained by checking the header of the first packet. We can partition the features into 3 "cost" (time delay) levels: level 1 features can be computed from the first packet; level 2 features can be computed at the end of the connection, using only information of the current connection; level 3 can be computed at the end of the connection, but require access to data of (many) other prior connections. By assigning a cost estimate to each level, we can obtain an estimate of the cost of each rule according to the features that is uses. Note that we cannot simply order the rules by their costs for real-time execution for the following reasons. First, the rules output by the classification algorithm, e.g., RIPPER, are often in a strict sequential order (e.g., "if rule 1 else rule 2 else ..."), and hence reordering the rules may result in unintended classification errors. Furthermore, even if the rules can be tested in strictly cost order without introducing classification error, many rules will still be tested (and fail to match) before a classification is made. That is, ordering the rules by their costs alone is not necessarily the optimal solution for quick model evaluation. We thus need to compute an "optimal schedule" for feature computation and rule testing to minimize model evaluation costs, and increase the response rate for real-time detection.
Ideally, we can have a few tests involving the low cost (i.e., level 1 and level 2) features to eliminate the majority of the rules that need to be checked, and thus eliminating the needs to compute some of the high cost features. In order to eliminate the need for testing a rule for intrusion I, we need a test of the form of F ==> not I, which can be derived from I ==> not F. We can compute the association rules that have the intrusion labels on the LHS and the low cost features on the RHS, and a confidence of 100%. We can easily find such associations for a number of intrusions, for example, port_scan ==> src_byes < 3. Note that most of these features are not used to detect the intrusions because they don't have predictive power. However, these associations are the "necessary" conditions for the intrusions, for example, "this connection is a port-scan attack only if src_bytes is less than 3", which is equivalent to "if the src_bytes is not less than 3, then this connection is not a port-scan attack". A rule for an intrusion can excluded because of the failure of its necessary condition, and as a results, its high-cost features need not be computed, unless they are needed for other candidate (remaining) rules.
Suppose that we have n detection rules. We use an n-bit vector as the remaining vector to indicate which rules still need to be checked. At the beginning, all bits are 1's. Each rule has a invalidating n-bit vector, where only the bit corresponding to the rule is 0 and all other bits are 1's. Each of the high cost features has a computing n-bit vector, where only the bits corresponding to the rules that require this feature are 1's.
For each intrusion label, we record its lowest cost necessary condition (if there are such conditions), according to the costs of the features involved. We sort all these necessary conditions according to the costs to produce the order for real-time condition checking. When examining a packet, or a (just completed) connection, if a necessary condition of an intrusion is violated, the corresponding invalidating bit vectors of the rules of the intrusion are used to AND the remaining vector and all the computing vectors for the high cost features. After all the necessary conditions are checked, we get all the features with non-zero computing vectors. These features are potentially useful because of the remaining rules that need to be checked. A single function call is made to compute all these features at once. This execution strategy reduces memory or disk access since these features compute statistical information on the past (stored) connections records. The remaining vector is then used to check the remaining rules one by one.
The main goal of our project is to build a development system so that effective, cost-sensitive and light ID models can be quickly built and deployed. We will also develop a real-time IDS equipped with our ID models to demonstrate the advanced capabilities of our development system. We describe our project plan as follows.
For the first year, we will concentrate on algorithm development. This includes: enhancing and integrating existing components of JAM, e.g., the data mining programs for audit data analysis, and the pattern encoding and analysis programs; and developing initial versions of the new algorithmic components. We will establish the capabilities of automated feature construction for anomaly detection, feature cost- and intrusion cost- sensitive learning, clustering light models, and finding low-cost "necessary conditions". We will begin building up relationships with other research projects to identify areas of collaboration, e.g., in defining and measuring cost factors, integration of systems, and future technology transfer etc. We will use experimentation to continuously evaluate our algorithms and guide new development, and to gain insight into what are the possible "goal-oriented" and "auto-focus" workflow operators, and what are the important cost factors to IDSs. Initial experiments will be carried out using locally gathered network, Unix, and Windows NT audit data. Starting the first year, we plan to do yearly integration of the tools developed at 3 institutions and participate in the DARPA ID evaluation to test the capabilities of our system.
For the second year, based on the experience and evaluation results from the first year, we will improve the existing algorithms and will focus on developing more advanced anomaly detection modeling algorithms (e.g., various probabilistic models), introducing more comprehensive cost metrics, building models that can be dynamically adapted to changing cost factors, combining multiple light models in cost-sensitive manners, and compiling efficient run-time schedules. We will perform integration and participate in the DARPA ID evaluation to identify improvements and remaining problem areas. Another major task is to make the beta-versions of our system as well as the extended real-time IDS(s) available for download, and analyze feedback from users.
For the third year, we focus on making improvements to our systems based on evaluations from DARPA evaluation and users. We plan a major effort to integrate all tools into a single system. We will implement the "goal-oriented" and "auto-focus" operators so that the system has an automated and intuitive workflow. We will write documentation and release our system to interested parties. We will once again participate in the DARPA ID evaluation. We will also actively explore technology transfer opportunities.
Throughout the whole project duration, we will attend regular PI meetings and visit other groups to exchange ideas and share technologies. We will also publish our findings in yearly major conferences so that our work can be reviewed critically from the scientific communities. We will submit to DARPA a final detailed technical report summarizing our algorithm development, evaluation results, and recommendations.
Most existing Intrusion Detection Systems (IDSs), e.g., USTAT (from UCSB), IDIOT (from Purdue), and EMERALD (from SRI), etc., are developed using pure knowledge-engineering approaches. The main advantage here is that experts can build focused and optimized pattern matching models. The main disadvantages are: first, due to the often incomplete expert and the complexities of the network systems, effectiveness of the IDSs is poor; second, due to the manual nature of the development process, IDSs are expensive and slow to build. Using our data mining systems, the inductively learned rules replace the manually coded intrusion patterns and profiles, and system features and measures are selected by considering the statistical patterns from the audit data. There are several important advantages here. First, the development cycle is shortened considerably because the data mining programs can be automatically (mechanically) applied to audit data. Second, the misuse and anomaly detection models can be more accurate because they are computed from extensively gathered audit data using tools that are based on statistical and information theories. Third, meta-learning, a framework to learn the correlation among multiple (distributed) models, can be used to facilitate the construction of multiple coordinated and distributed light detection models, which is the key to both efficiency and survivability (i.e., avoiding single point of failure) of an IDS. Forth, cost factors can be systematically incorporated into our machine learning algorithms to produce cost-sensitive intrusion detection models. It should be noted that our approach requires the use of a large amount of quality audit data to train the models. However, this "disadvantage" is not as serious as it may seem. Many organizations can afford to extensively collect and store system audit data for analysis because of the low costs of hard disks. More importantly, recent DARPA sponsored efforts in IDSs experimentation and evaluation, e.g., work done in MIT Lincoln Labs, provide a wealth of audit data for model building and testing. Efforts with CIDF will also facilitate the sharing and distribution of new intrusion data. Another prerequisite is that audit data must be preprocessed into tabular forms that are suitable for data mining programs. There are freely available robust audit data preprocessing programs, e.g., the packet filtering and reassembling engine of Bro and the BSM data parser of USTAT, that be can be easily customized. We have extensive experience in using these programs.
The work on fraud detection in the cases of cellular phone fraud and credit card fraud provide two excellent exemplar demonstrating the utility of data mining in learning models of errant or abnormal activities in real time applications. Researches in this area conducted by the PI's on this proposal have lead to the more recent work on IDS. In our initial work, we studied the approach espoused by Stephanie Forrest on light models of system call data. However, we approached the problem from a different perspective. In Forrest's work, an initial assumption is made that patterns of intrusions would manifest themselves in short sequences of system call data. In that work, an "n-gram" database of sequential system calls are used to represent the "normal" behavior of some program that would be used to identify abnormal behavior of that program when detecting attacks. Some of our prior DARPA-sponsored research focused on replicating her results. We found that, although the approach is interesting and useful, it lacked an ability to generalize to a wider range of attacks than those simulated in that work. Furthermore, there was much more additional information available from the audit stream that could improve detection capabilities but which were completely ignored in that work. The follow-on research conducted on JAM and the MADAM ID component for IDS demonstrated that indeed more sophisticated models could be built automatically to produce effective models for intrusion detection.
Recently, several other groups have been following a similar path, for example the groups at George Mason University and RST. In these and other cases, once again an initial assumption is made about which features or events should be inspected and extracted from an audit stream, which serve as the basis for developing or learning models. In our work, the feature construction process is in itself the subject of the overall detection problem. Traditionally, machine learning research focuses on devising algorithms that generate accurate models. Instances and features that describe these instances are often assumed to be provided. However, in our work the audit stream contains raw data that need to be "preprocessed" to obtain the desired features. That is, features are not readily available. We treat feature construction itself as a learning problem and devise techniques, with the help of some domain knowledge, to identify patterns that can be used as features in an ID model. Though, in our initial work, the ID model is simply generated by subtracting features constructed from normal traffic from features generated from attack traffic, we call this first-tier models in our three-tier approach, our plan is to apply learning algorithms to generalize from these first-tier models.
Audit data are continuously collected and stored. The newly acquired information reflects the most recent access pattern of the users. Knowledge discovered from older data might become invalid. Also, attack signatures get updated or become obsolete over time. To process a continuous stream of data and temporally adapt to new attacks, one approach is to merge the old and new data and apply learning algorithms. This would require a large amount of computation effort and hence cannot adapt to new attacks swiftly. Another approach is to use incremental learning algorithms, which allow new data to be processed and the previously learned concept updated. However, it does not provide a means for removing irrelevant knowledge gathered in the past. Our multi-model approach allows models to be learned from new data and old irrelevant models to be removed. Unlike the monolithic approach of updating one model using incremental learning, our modular multi-model approach facilitates adaptation over time, and removal of out-of-date knowledge. Furthermore, our approach is scalable to processing a continuous stream of large amounts of data.
It is imperative that we perform regular experiments to scientifically evaluate our systems. We will perform experiments in several levels and iterations. First, when a new or improved algorithm or software component is developed, experiments are conducted to test its validity (i.e., whether it works or not) and evaluate its improvements over the previous version. Such experiments may involve manual tasks since a component may be tested alone without other compatible components in the integrated and automated system. A set of audit data is kept for repeated experiments. The data set can be a subset of the DARPA ID evaluation dataset, or a locally gathered dataset that emulates a typical network environment. We will document detailed report on all experiments. Second, when all components are integrated into a single software package, we will conduct experiments to test whether the components interface with each other well, and whether using the integrated system provide measurable benefits, e.g., shorten ID model development cycle, better ID models, etc. The integrated system will be used to submit ID models to the yearly DARPA ID evaluation. Third, when a component(s) or the integrated system is integrated with systems developed by other groups, we will conduct experiments to test the feasibilities of using standard interfaces, e.g., CIDF, and to evaluate combining technologies from multiple groups can yield better intrusion detection performance.
We will seek to integrate our system (or components) with solutions from the IA&S communities. In particular, we will need to apply techniques developed in computer security risk assessment to define and measure the cost factors related to IDSs. We also plan a number of integration projects. We will integrate our automated feature construction component with Neural Net based Windows NT anomaly detection system developed at RST (Reliable Software Technologies). This project will test the generality of our algorithms. We will integrate our system with Bro or NFR in several aspects. First, we will measure the computational features using these real-time IDSs. Second, we will develop translators to mechanically convert the cost sensitive ID models produced by our system into real-time modules of these IDSs. Third, we will test and compare the performance gains when using the efficient scheduling approach based on low-cost "necessary conditions", various cost-sensitive modeling techniques, and various light modeling and cost-sensitive combining techniques.
The three co-Principal Investigators are Wenke Lee from North Carolina State University, Sal Stolfo from Columbia University, and Phil Chan from Florida Institute of Technology.
Dr. Wenke Lee received his Ph.D. from Columbia University in 1999. Under the supervision of Professor Sal Stolfo, for his thesis research, Dr. Lee designed and implemented MADAM ID (Mining Audit Data form Automated Models for Intrusion Detection), a component of JAM. The results from the 1998 DARPA Intrusion Detection Evaluation showed that the models produced by MADAM ID had one of the best performance among all participants. Dr. Lee has published several papers related to his thesis research in premier data mining and security conferences, and has won one best paper award and two honorable mentions. Dr. Lee is currently an assistant professor in Computer Science at North Carolina State University.
Dr. Sal Stolfo is a tenured full professor in Computer Science at Columbia University. Dr. Stolfo has supervised more than ten Ph.D.s and has done research in wide ranging fields, including, parallel architecture, speech recognition, machine learning, and most recently, digital government, and fraud and intrusion detection. Dr. Stolfo has had several DARPA contracts. Dr. Stolfo was the PI for the DARPA sponsored JAM project, where data mining and meta-learning technologies were developed and successfully applied to fraud and intrusion detection. Dr. Stolfo will be the program co-chair for the 2000 ACM SIGKDD conference.
Dr. Phil Chan received his Ph.D. from Columbia University in 1996. Dr. Chan developed the concept of meta-learning in his Ph.D. thesis. The JAM project was largely based on meta-learning technologies. Since 1995, Dr. Chan is an assistant professor in Computer Science at Florida Institute of Technology. Dr. Chan was a co-PI for the JAM project, and actively contributed to development of JAM's cost-sensitive learning and distributed data mining technologies.