|
Wenke Lee and Salvatore J. Stolfo
Computer Science Department
Columbia University
500 West 120th Street, New York, NY 10027
{wenke,sal}@cs.columbia.edu
The security of a computer system is compromised when an intrusion takes place. An intrusion can be defined [HLMS90] as "any set of actions that attempt to compromise the integrity, confidentiality or availability of a resource". Intrusion prevention techniques, such as user authentication (e.g. using passwords or biometrics), avoiding programming errors, and information protection (e.g., encryption) have been used to protect computer systems as a first line of defense. Intrusion prevention alone is not sufficient because as systems become ever more complex, there are always exploitable weakness in the systems due to design and programming errors, or various "socially engineered" penetration techniques. For example, after it was first reported many years ago, exploitable "buffer overflow" still exists in some recent system software due to programming errors. The policies that balance convenience versus strict control of a system and information access also make it impossible for an operational system to be completely secure.
Intrusion detection is therefore needed as another wall to protect computer systems. The elements central to intrusion detection are: resources to be protected in a target system, i.e., user accounts, file systems, system kernels, etc; models that characterize the "normal" or "legitimate" behavior of these resources; techniques that compare the actual system activities with the established models, and identify those that are "abnormal" or "intrusive".
Many researchers have proposed and implemented different models which define different measures of system behavior, with an ad hoc presumption that normalcy and anomaly (or illegitimacy) will be accurately manifested in the chosen set of system features that are modeled and measured. Intrusion detection techniques can be categorized into misuse detection, which uses patterns of well-known attacks or weak spots of the system to identify intrusions; and anomaly detection, which tries to determine whether deviation from the established normal usage patterns can be flagged as intrusions.
Misuse detection systems, for example [KS95] and STAT [IKP95], encode and match the sequence of "signature actions" (e.g., change the ownership of a file) of known intrusion scenarios. The main shortcomings of such systems are: known intrusion patterns have to be hand-coded into the system; they are unable to detect any future (unknown) intrusions that have no matched patterns stored in the system.
Anomaly detection (sub)systems, such as IDES [LTG+92], establish normal usage patterns (profiles) using statistical measures on system features, for example, the CPU and I/O activities by a particular user or program. The main difficulties of these systems are: intuition and experience is relied upon in selecting the system features, which can vary greatly among different computing environments; some intrusions can only be detected by studying the sequential interrelation between events because each event alone may fit the profiles.
Our research aims to eliminate, as much as possible, the manual and ad-hoc elements from the process of building an intrusion detection system. We take a data-centric point of view and consider intrusion detection as a data analysis process. Anomaly detection is about finding the normal usage patterns from the audit data, whereas misuse detection is about encoding and matching the intrusion patterns using the audit data. The central theme of our approach is to apply data mining techniques to intrusion detection. Data mining generally refers to the process of (automatically) extracting models from large stores of data [FPSS96]. The recent rapid development in data mining has made available a wide variety of algorithms, drawn from the fields of statistics, pattern recognition, machine learning, and database. Several types of algorithms are particularly relevant to our research:
We are developing a systematic framework for designing, developing and evaluating intrusion detection systems. Specifically, the framework consists of a set of environment-independent guidelines and programs that can assist a system administrator or security officer to
The key advantage of our approach is that it can automatically generate concise and accurate detection models from large amount of audit data. The methodology itself is general and mechanical, and therefore can be used to build intrusion detection systems for a wide variety of computing environments.
The rest of the paper is organized as follows: Section 2 describes our experiments in building classification models for sendmail and network traffic. Section 3 presents the association rules and frequent episodes algorithms that can be used to compute a set of patterns from audit data. Section 4 briefly highlights the architecture of our proposed intrusion detection system. Section 5 outlines our future research plans.
Stephanie Forrest provided us with a set of traces of the sendmail program used in her experiments [FHSL96]. We applied machine learning techniques to produce classifiers that can distinguish the exploits from the normal runs.
| System Call Sequences (length 7) | Class Labels |
| 4 2 66 66 4 138 66 | "normal" |
| ... | ... |
| 5 5 5 4 59 105 104 | "abnormal" |
| ... | ... |
We applied RIPPER [Coh95], a rule learning program, to our training data. The following learning tasks were formulated to induce the rule sets for normal and abnormal system call sequences:
RIPPER outputs a set of if-then rules for the "minority" classes, and a default "true" rule for the remaining class. The following exemplar RIPPER rules were generated from the system call data:
normal:- p2=104, p7=112. [meaning: if p2 is 104 (vtimes) and p7 is 112 (vtrace) then the sequence is "normal"]normal:- p6=19, p7=105. [meaning: if p6 is 19 (lseek) and p7 is 105 (sigvec) then the sequence is "normal"]
...
abnormal:- true. [meaning: if none of the above, the sequence is "abnormal"]
These RIPPER rules can be used to predict whether a sequence is "abnormal" or "normal". But what the intrusion detection system needs to know is whether the trace being analyzed is an intrusion or not. We use the following post-processing scheme to detect whether a given trace is an intrusion based on the RIPPER predictions of its constituent sequences:
This scheme is an attempt to filter out the spurious prediction errors. The intuition behind this scheme is that when an intrusion actually occurs, the majority of adjacent system call sequences are abnormal; whereas the prediction errors tend to be isolated and sparse. In [FHSL96], the percentage of the mismatched sequences (out of the total number of matches (lookups) performed for the trace) is used to distinguish normal from abnormal. The "mismatched" sequences are the abnormal sequences in our context. Our scheme is different in that we look for abnormal regions that contain more abnormal sequences than the normal ones, and calculate the percentage of abnormal regions (out of the total number of regions). Our scheme is more sensitive to the temporal information, and is less sensitive to noise (errors).
RIPPER only outputs rules for the "minority" class. For example, in our experiments, if the training data has fewer abnormal sequences than the normal ones, the output RIPPER rules can be used to identify abnormal sequences, and the default (everything else) prediction is normal. We conjectured that a set of specific rules for normal sequences can be used as the "identity" of a program, and thus can be used to detect any known and unknown intrusions (anomaly intrusion detection). Whereas having only the rules for abnormal sequences only gives us the capability to identify known intrusions (misuse intrusion detection).
| % abn. | % abn. in experiment | ||||
| Traces | [FHSL96] | A | B | C | D |
| sscp-1 | 5.2 | 41.9 | 32.2 | 40.0 | 33.1 |
|---|---|---|---|---|---|
| sscp-2 | 5.2 | 40.4 | 30.4 | 37.6 | 33.3 |
| sscp-3 | 5.2 | 40.4 | 30.4 | 37.6 | 33.3 |
| syslog-r-1 | 5.1 | 30.8 | 21.2 | 30.3 | 21.9 |
| syslog-r-2 | 1.7 | 27.1 | 15.6 | 26.8 | 16.5 |
| syslog-l-1 | 4.0 | 16.7 | 11.1 | 17.0 | 13.0 |
| syslog-l-2 | 5.3 | 19.9 | 15.9 | 19.8 | 15.9 |
| decode-1 | 0.3 | 4.7 | 2.1 | 3.1 | 2.1 |
| decode-2 | 0.3 | 4.4 | 2.0 | 2.5 | 2.2 |
| sm565a | 0.6 | 11.7 | 8.0 | 1.1 | 1.0 |
| sm5x | 2.7 | 17.7 | 6.5 | 5.0 | 3.0 |
| sendmail | 0 | 1.0 | 0.1 | 0.2 | 0.3 |
We compare the results of the following experiments that have different distributions of abnormal versus normal sequences in the training data:
Table 2 shows the results of using the classifiers from these experiments to analyze the traces. We report here the percentage of abnormal regions (as measured by our post-processing scheme) of each trace, and compare our results with Forrest et al., as reported in [FHSL96]. From Table 2, we can see that in general, intrusion traces generate much larger percentages of abnormal regions than the normal traces. We call these measured percentages the "scores" of the traces. In order to establish a threshold score for identifying intrusion traces, it is desirable that there is a sufficiently large gap between the scores of the normal sendmail traces and the low-end scores of the intrusion traces. Comparing experiments that used the same sequence length, we observe that such a gap in A, 3.4, is larger than the gap in C, 0.9; and 1.9 in B is larger than 0.7 in D. The RIPPER rules from experiments A and B describe the patterns of the normal sequences. Here the results show that these rules can be used to identify the intrusion traces, including those not seen in the training data, namely, the decode traces, the sm565a and sm5x traces. This confirms our conjecture that rules for normal patterns can be used for anomaly detection. The RIPPER rules from experiments C and D specify the patterns of abnormal sequences in the intrusion traces included in the training data. The results indicate that these rules are very capable of detecting the intrusion traces of the "known" types (those seen in the training data), namely, the sscp-3 trace, the syslog-remote-2 trace and the syslog-local-2 trace. But comparing with the rules from A and B, the rules in C and D perform poorly on intrusion traces of "unknown" types. This confirms our conjecture that rules for abnormal patterns are good for misuse intrusion detection, but may not be as effective in detecting future ("unknown") intrusions.
The results from Forrest et al. showed that their method required a very low threshold in order to correctly detect the decode and sm565a intrusions. While the results here show that our approach generated much stronger "signals" of anomalies from the intrusion traces, it should be noted that their method used all of the normal traces but not any of the intrusion traces in training.
The learning tasks were formulated as follows:
RIPPER outputs rules in the following form:
38 :- p3=40, p4=4. [meaning: if p3 is 40 (lstat) and p4 is 4 (write), then the 7th system call is 38 (stat).]...
5:- true. [meaning: if none of the above, then the 7th system calls is 5 (open).]
Each of these RIPPER rules has some "confidence" information: the number of matched examples (records that conform to the rule) and the number of unmatched examples (records that are in conflict with the rule) in the training data. For example, the rule for "38 (stat)" covers 12 matched examples and 0 unmatched examples. We measure the confidence value of a rule as the number of matched examples divided by the sum of matched and unmatched examples. These rules can be used to analyze a trace by examining each sequence of the trace. If a violation occurs (the actual system call is not the same as predicted by the rule), the "score" of the trace is incremented by 100 times the confidence of the violated rule. For example, if a sequence in the trace has p3=40 and p4=4, but p7=44 instead of 38, the total score of the trace is incremented by 100 since the confidence value of this violated rule is 1. The averaged score (by the total number of sequences) of the trace is then used to decide whether an intrusion has occurred.
| averaged score of violations | ||||
| Traces | Exp. A | Exp. B | Exp. C | Exp. D |
| sscp-1 | 24.1 | 13.5 | 14.3 | 24.7 |
| sscp-2 | 23.5 | 13.6 | 13.9 | 24.4 |
| sscp-3 | 23.5 | 13.6 | 13.9 | 24.4 |
| syslog-r-1 | 19.3 | 11.5 | 13.9 | 24.0 |
| syslog-r-2 | 15.9 | 8.4 | 10.9 | 23.0 |
| syslog-l-1 | 13.4 | 6.1 | 7.2 | 19.0 |
| syslog-l-2 | 15.2 | 8.0 | 9.0 | 20.2 |
| decode-1 | 9.4 | 3.9 | 2.4 | 11.3 |
| decode-2 | 9.6 | 4.2 | 2.8 | 11.5 |
| sm565a | 14.4 | 8.1 | 9.4 | 20.6 |
| sm5x | 17.2 | 8.2 | 10.1 | 18.0 |
| sendmail | 5.7 | 0.6 | 1.2 | 12.6 |
Table 3 shows the results of the following experiments:
We can see from Table 3 that the RIPPER rules from experiments A and B are effective because the gap between the score of normal sendmail and the low-end scores of intrusion traces, 3.9, and 3.3 respectively, are large enough. However, the rules from C and D perform poorly. Since C predicts the middle system call of a sequence of length 11 and D predicts the 7th system call, we reason that the training data (the normal traces) has no stable patterns for the 6th or 7th position in system call sequences.
We need to search for a more predictive classification model so that the anomaly detector has higher confidence in flagging intrusions. Improvement in accuracy can come from adding more features, rather than just the system calls, into the models of program execution. For example, the directories and the names of the files touched by a program can be used. In [Fra94], it is reported that as the number of features increases from 1 to 3, the classification error rate of their network intrusion detection system decreases dramatically. Furthermore, the error rate stabilizes after the size of the feature set reaches 4, the optimal size in their experiments. Many operating systems provide auditing utilities, such as the BSM audit of Solaris, that can be configured to collect abundant information (with many features) of the activities in a host system. From the audit trails, information about a process (program) or a user can then be extracted. The challenge now is to efficiently compute accurate patterns of programs and users from the audit data.
A key assumption in using a learning algorithm for anomaly detection (and to some degree, misuse detection) is that the training data is nearly "complete" with regard to all possible "normal" behavior of a program or user. Otherwise, the learned detection model can not confidently classify or label an unmatched data as "abnormal" since it can just be an unseen "normal" data. For example, the experiments in Section 2.1.3 used 80% of "normal" system call sequences; whereas the experiments in Section 2.1.2 actually required all "normal" sequences in order to pre-label the "abnormal" sequences to create the training data. During the audit data gathering process, we want to ensure that as much different normal behavior as possible is captured. We first need to have a simple and incremental (continuously learning) summary measure of an audit trail so that we can update this measure as each new audit trail is processed, and can stop the audit process when the measure stabilizes. In Section 3, we propose to use the frequent intra- and inter- audit record patterns as the summary measure of an audit trail, and describe the algorithms to compute these patterns.
Since tcpdump output is not intended specifically for security purposes, we had to go through multiple iterations of data pre-processing to extract meaningful features and measures. We studied TCP/IP and its security related problems, for example [Ste84,Pax97,ABH+96,Pax98,Bel89,PV98], for guidelines on the protocols and the important features that characterize a connection.
Since UDP is connectionless (no connection state), we simply treat each packet as a connection.
A connection record, in preparation of data mining, now has the following fields (features): start time, duration, participating hosts, ports, the statistics of the connection (e.g., bytes sent in each direction, resent rate, etc.), flag ("normal" or one of the recorded connection/termination errors), and protocol (TCP or UDP). From the ports, we know whether the connection is to a well-known service, e.g., http (port 80), or a user application.
We call the host that initiates the connection, i.e., the one that sends the first SYN, as the source, and the other as the destination. Depending on the direction from the source to the destination, a connection is in one of the three types: out-going - from the LAN to the external networks; in-coming - from the external networks to the LAN; and inter-LAN - within the LAN. Taking the topologies of the network into consideration is important in network intrusion detection. Intuitively, intrusions (which come from outside) may first exhibit some abnormal patterns (e.g., penetration attempts) in the in-coming connections, and subsequently in the inter-LAN (e.g., doing damage to the LAN) and/or the out-going (e.g., stealing/uploading data) connections. Analyzing these types of connections and constructing corresponding detection models separately may improve detection accuracy.
We again applied RIPPER to the connection data. The resulting classifier characterizes the normal patterns of each service in terms of the connection features. When using the classifier on the testing data, the percentage of misclassifications on each tcpdump data set is reported. Here a misclassification is the situation where the the classifier predicts a destination service (according to the connection features) that is different from the actual. This misclassification rate should be very low for normal connection data and high for intrusion data. The intuition behind this classification model is straightforward: when intrusions take place, the features (characteristics) of connections to certain services, for example, ftp, are different from the normal traffic patterns (of the same service).
The results from the first round of experiments, as shown in Table 4, were not very good: the differences in the misclassification rates of the normal and intrusion data were small, except for the inter-LAN traffic of some intrusions.
| % misclassification (by traffic type) | |||
| Data | out-going | in-coming | inter-LAN |
| normal | 3.91% | 4.68% | 4% |
| intrusion1 | 3.81% | 6.76% | 22.65% |
| intrusion2 | 4.76% | 7.47% | 8.7% |
| intrusion3 | 3.71% | 13.7% | 7.86% |
We then redesigned our set of features by adding some continuous and intensity measures into each connection record:
| % misclassification (by traffic type) | |||
| Data | out-going | in-coming | inter-LAN |
| normal | 0.88% | 0.31% | 1.43% |
| intrusion1 | 2.54% | 27.37% | 20.48% |
| intrusion2 | 3.04% | 27.42% | 5.63% |
| intrusion3 | 2.32% | 42.20% | 6.80% |
These additional temporal-statistical features provide additional information of the network activity from a continuous perspective, and provide more insight into anomalies. For example, a low rate of error due to innocent attempts and network glitches in a short time span is expected, but an excess beyond the (averaged) norm indicates anomalous activity. Table 5 shows the improvement of adding these features. Here, using a time interval of 30 seconds (i.e., n=30s), we see that the misclassification rates on the intrusion data are much higher than the normal data, especially for the in-coming traffic. The RIPPER rule set (the classifier) has just 9 rules and 25 conditions. For example, one rule says "if the average number of bytes from source to destination (of the connections to the same service) is 0, and the percentage of control packets in the current connection is 100%, then the service is auth".
To understand the effects of the time intervals on the misclassification rates, we ran the experiments using various time intervals: 5s, 10s, 30s, 60s, and 90s. The effects on the out-going and inter-LAN traffic were very small. However, as Figure 1 shows, for the in-coming traffic, the misclassification rates on the intrusion data increase dramatically as the time interval goes from 5s to 30s, then stabilizes or tapers off afterwards.
There are also much needed improvements to our current approach: First, deciding upon the right set of features is difficult and time consuming. For example, many trials were attempted before we came up with the current set of features and time intervals. We need useful tools that can provide insight into the patterns that may be exhibited in the data. Second, we should provide tools that can help administrative staff understand the nature of the anomalies.
The meta detection model is actually a hierarchy of detection models. At the bottom, the base classifiers take audit data as input and output evidence to the meta classifier, which in turn outputs the final assertion.
Our research activities in JAM [SPT+97], which focus on the accuracy and efficiency of meta classifiers, will contribute significantly to our effort in building meta detection models.
trn --> rec.humor; [0.3, 0.1],
which indicates that 30% of the time when the user invokes trn, he or she is reading the news in rec.humor, and reading this newsgroup accounts for 10% of the activities recorded in his or her command history file. Here 0.3 is the confidence and 0.1 is the support.The motivation for applying the association rules algorithm to audit data are:
Our implementation follows the general association rules algorithm, as described in [Sri96].
home, research --> theory; [0.2, 0.05], [30s]
which indicates that when the home page and the research guide are visited (in that order), in 20% of the cases the theory group's page is visited subsequently within the same 30s time window, and this sequence of visits occurs 5% of the total (the 30s) time windows in the log file (that is, approximately 5% of all the records).We seek to apply the frequent episodes algorithm to analyze audit trails since there is evidence that the sequence information in program executions and user commands can be used to build profiles for anomaly detection [FHSL96,LB97]. Our implementation followed the description in [MTV95].
When the rule set stabilizes (there are no new rules added), we can stop the data gathering process since we have produced a near complete set of audit data for the normal runs. We then prune the rule set by eliminating the rules with low match_count, according to a user-defined threshold on the ratio of match_count over the total number of audit trails. The system builders can then use the correlation information in this final profile rule set to select a subset of the relevant features for the classification tasks. We plan to build a support environment to integrate the process of user selection of features, computing a classifier (according to the feature set), and presenting the performance of the classifier. Such a support system can speed up the iterative feature selection process, and help ensure the accuracy of a detection model.
We believe that the discovered patterns from (the extensively gathered) audit data can be used directly for anomaly detection. We compute a set of association rules and frequent episodes from a new audit trail, and compare it with the established profile rule set. Scoring functions can be used to evaluate the deviation scores for: missing rules with high support, violation (same antecedent but different consequent) of rules with high support and confidence, new (unseen) rules, and significant changes in support of rules.
We wanted to study how the frequent episodes algorithm can help us determine the time window used in gathering temporal-statistical features. We ran the algorithm on the "normal" in-coming connection records (without the temporal-statistical features). We set the program to produce two types of output: raw serial and parallel episodes (no rules were generated) and serial episode rules. For raw episodes, we used min_fr=0.3. And for serial episode rules, we used min_fr=0.1 and min_conf=0.6 and 0.8. We used different time window sizes (win): 2s, 5s, 10s, 15s, 30s, 45s, 60s, 90s, 120s, 150s, and 200s; and recorded the number of frequent episodes generated on each win. In Figure 2 we see that the number of frequent episodes (raw episodes or serial episode rules) increases sharply as win goes from 2s to 30s, it then gradually stabilizes (note that by the nature of the frequent episodes algorithm, the number of episodes can only increase as win increases). This phenomenon coincides with the trends in Figure 1. Note that here we made the particular choice of the parameters (i.e., min_fr, min_conf) only for the purpose of controlling the maximum size of the episode rule set. Different settings exhibited the same phenomenon. We conjecture (and will verify with further experiments on other data sets) that we can use this technique to analyze data streams and automatically discover the most important temporal measure: the time window size, i.e., the period of time within which to measure appropriate statistical features to maximize classifier accuracy. Intuitively, the first requirement of a time window size is that its set of sequence patterns is stable, that is, sufficient patterns are captured and noise is small.
We also ran both the association rules and frequent episodes programs on all the in-coming connection data, and compared the rule sets from the normal data with the intrusion data. The purpose of this experiment was to determine how these programs can provide insight into the (possible) patterns of intrusions. The frequent episodes generated were serial episode rules with win=30s, min_fr=0.1 and min_conf=0.8. The associations rules were generated using min_support=0.3 and min_confidence=0.9. We manually examined and compared the rule sets to look for "unique" patterns that exist in the intrusion data (but not in the normal data). Here are some results:
src_srv = "ftp-data", src_srv = "user-apps" --> src_srv = "ftp-data"; [0.96, 0.11], [30s]This rule means: when a connection with a user application as the source service follows a connection with ftp-data, 96% of the cases, a connection with ftp-data follows and falls into the same time window (30s); and this patterns occur 11% of the time. The unique association rules are related to "destination service is a user application", for example,
dst_srv = "user-apps" --> duration = 0, dst_to_src_bytes = 0; [0.9, 0.33]
This rule means: when the destination service of a connection is a user application, 90% of the cases, the duration and the number of data bytes from the destination to the source are both 0; and this pattern occurs 33% of the time.
dst_srv = "auth" --> flag = "unwanted_syn_ack"; [0.82, 0.1], [30s]and
dst_srv = "auth" --> dst_srv = "user-apps", dst_srv = "auth"; [0.82, 0.1], [30s]
There are a significant number of unique association rules in regard to "smtp is the source application". Many of these rules suggest connection error of smtp, for example,
src_srv = "smtp" --> duration = 0, flag = "unwanted_syn_ack", dst_srv = "user-apps"; [1.0, 0.38]
These rules may provide hints about the intrusions. For example, the unique (not normal) serial episodes in intrusion1 and intrusion2 reveal that there are a large number of ftp data transfer activities; whereas the unique serial episodes in intrusion3 suggest that a large number of connections to the auth service were attempted.
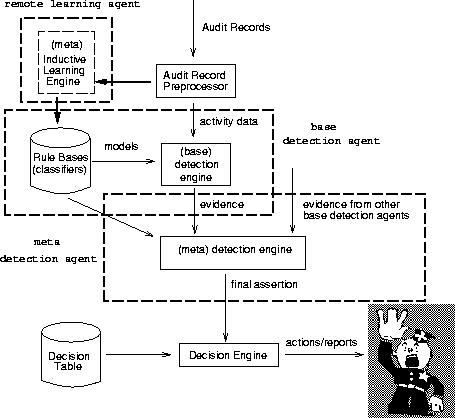
We propose a system architecture, as shown in Figure 3, that includes two kinds of intelligent agents: the learning agents and the detection agents. A learning agent, which may reside in a server machine for its computing power, is responsible for computing and maintaining the rule sets for programs and users. It produces both the base detection models and the meta detection models. The task of a learning agent, to compute accurate models from very large amount of audit data, is an example of the "scale-up" problem in machine learning. We expect that our research in agent-based meta-learning systems [SPT+97] will contribute significantly to the implementation of the learning agents. Briefly, we are studying how to partition and dispatch data to a host of machines to compute classifiers in parallel, and re-import the remotely learned classifiers and combine an accurate (final) meta-classifier, a hierarchy of classifiers [CS93].
A detection agent is generic and extensible. It is equipped with a (learned and periodically updated) rule set (i.e., a classifier) from the remote learning agent. Its detection engine "executes" the classifier on the input audit data, and outputs evidence of intrusions. The main difference between a base detection agent and the meta detection agent is: the former uses preprocessed audit data as input while the later uses the evidence from all the base detection agents. The base detection agents and the meta detection agent need not be running on the same host. For example, in a network environment, a meta agent can combine reports from (base) detection agents running on each host, and make the final assertion on the state of the network.
The main advantages of such a system architecture are:
We are in the initial stages of our research, much remains to be done including the following tasks: